Hot Chips 2020 Live Blog: Keynote Day 2, Dan Belov of Deepmind (1:30pm PT)
by Dr. Ian Cutress on August 18, 2020 4:25 PM EST
04:26PM EDT - Keynote for Day 2 of Hot Chips is from Dan Belov of Deepmind
04:27PM EDT - Deepmind is the company that created the AlphaGo program that played professional Go champion Lee Sedol in 2016, with the final score of 4-1 in favor of the artificial intelligence.
04:27PM EDT - This will likely be an update to what’s going on at Deepmind (now owned by Alphabet) and what they’re planning for the future of AI. We might get some insight as to how the company is working with other departments inside Alphabet – it has been cited that Deepmind has used its algorithms to increase the efficiency of cooling inside Google’s datacenters, for example.

04:33PM EDT - AI research at scale
04:33PM EDT - No formal training in hardware or systems - purely only a software guy

04:34PM EDT - Desire to build bigger and bigger machines
04:34PM EDT - Intro to Deepmind

04:35PM EDT - Deepmind - An Apollo Program for AI

04:35PM EDT - Research Institute inside Alphabet, 400 researchers
04:35PM EDT - Independent of Alphabet but backed by them

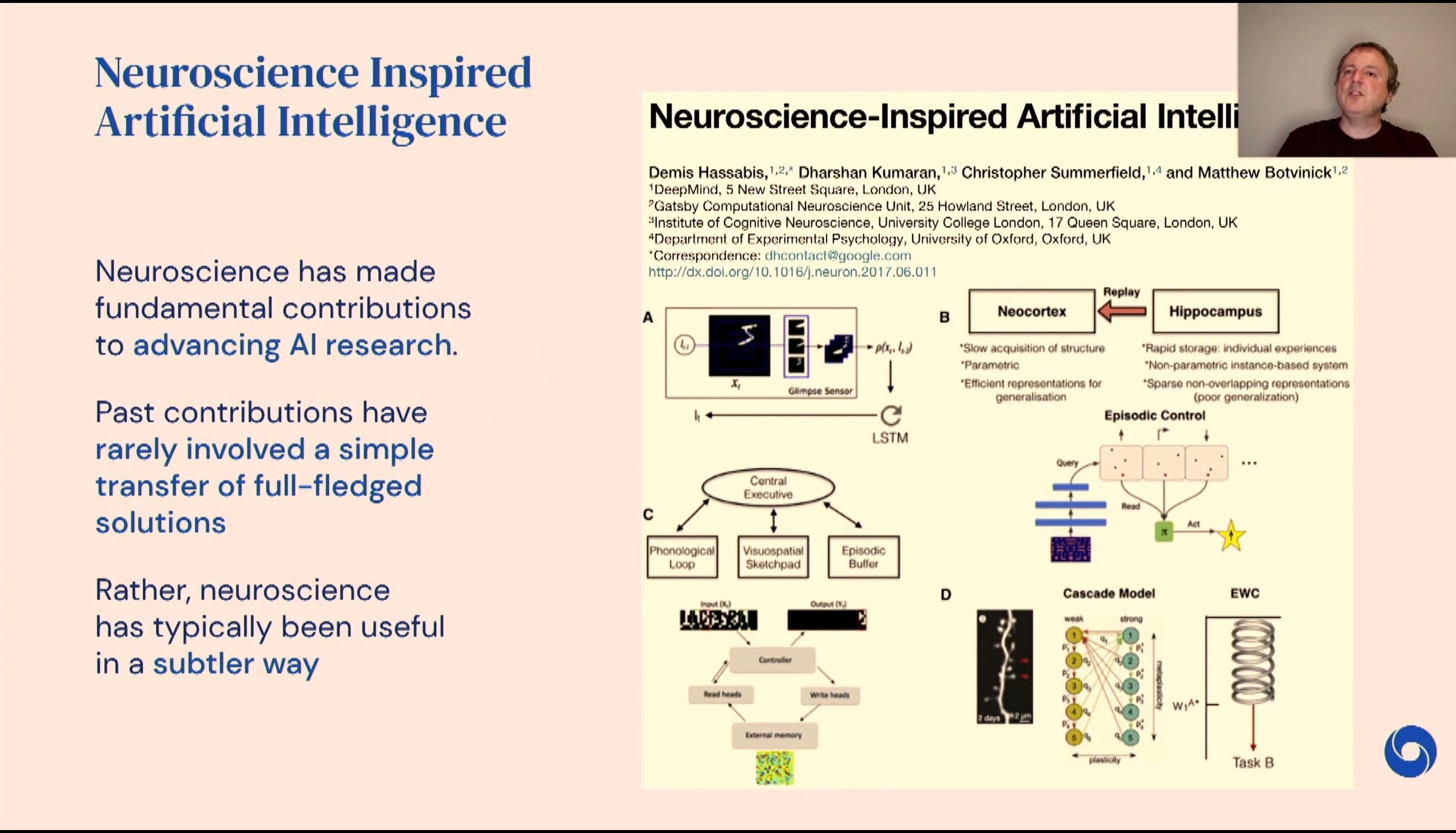
04:36PM EDT - DM has a unique approach to AI
04:36PM EDT - Neuroscience can act as a catalyst
04:36PM EDT - Neuro-physical phenomena
04:37PM EDT - Research using games
04:37PM EDT - Easy rules to test new approaches in parallel simulations
04:37PM EDT - Physically accurate simulations as required
04:37PM EDT - Such as playing breakout with RL

04:38PM EDT - Took four hours of training - minimum effort for maximum game
04:38PM EDT - Some of the solutions are very human like
04:38PM EDT - 2019 - solving puzzles in the real world
04:38PM EDT - Sequences of low level actions
04:39PM EDT - Task that is unlikely to be solved by random interaction
04:39PM EDT - Performing human level or better



04:39PM EDT - Machine Learning is about creating new knowledge, using the present klnowledge, to solve a large diversity of novel problem
04:40PM EDT - Recipes to train programs
04:40PM EDT - generalise to apply to new interactions

04:40PM EDT - Supervised DL - inferring knowledge from observations
04:40PM EDT - Iron Law of Deep Learning: More is More
04:41PM EDT - More diverse data, bigger network, more compute, gives better results
04:41PM EDT - Networks are growing 3x per year on average
04:41PM EDT - Reinforcement learning


04:41PM EDT - Make good decisions by learning from experience
04:42PM EDT - Maximise total reward during lifetime of agent
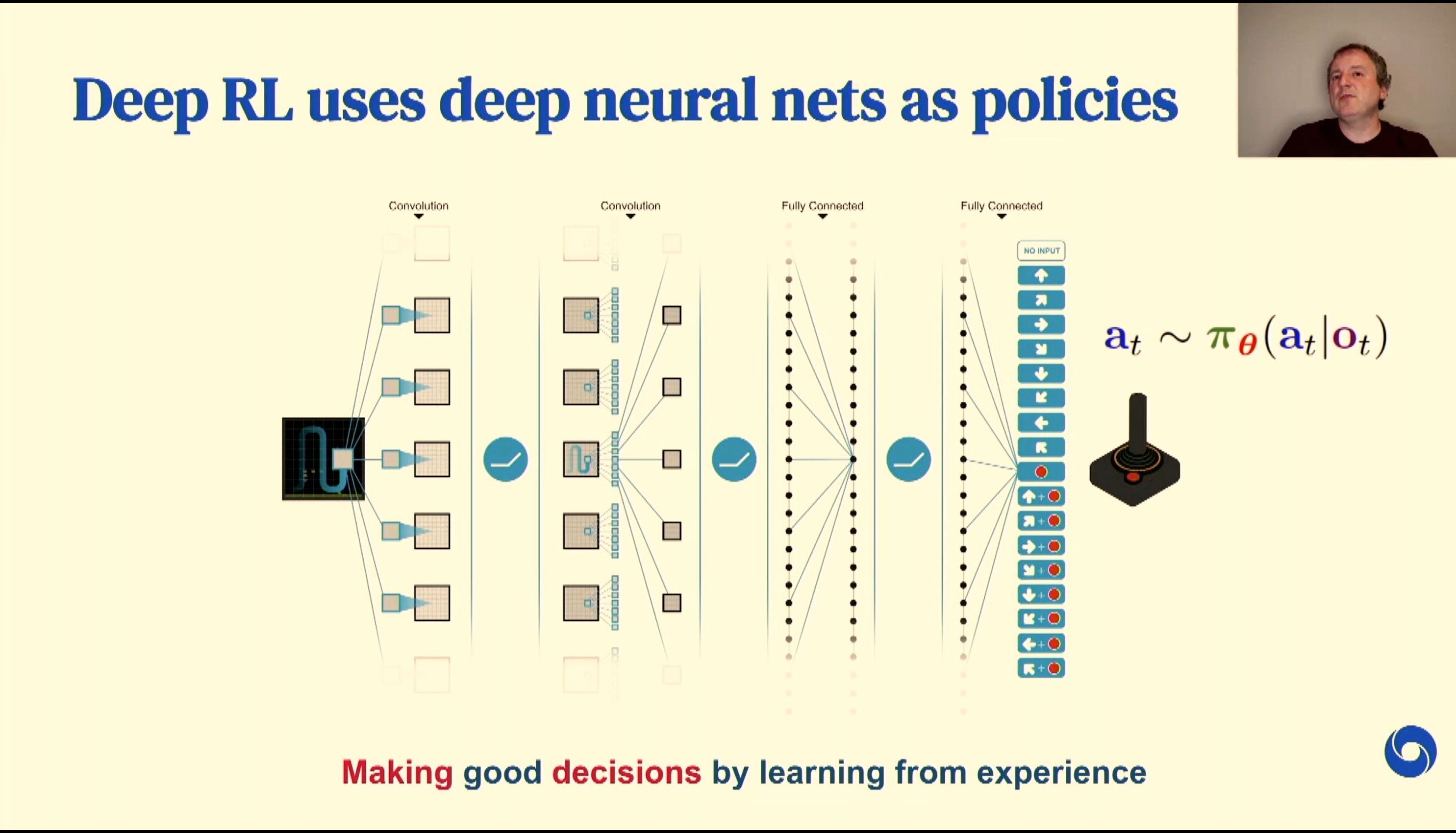
04:42PM EDT - All about the value function
04:43PM EDT - How to measure success, as in the real world
04:43PM EDT - future rewards exponentially decay
04:43PM EDT - predicting which future states give the best reward
04:43PM EDT - train networks against future values of themselves

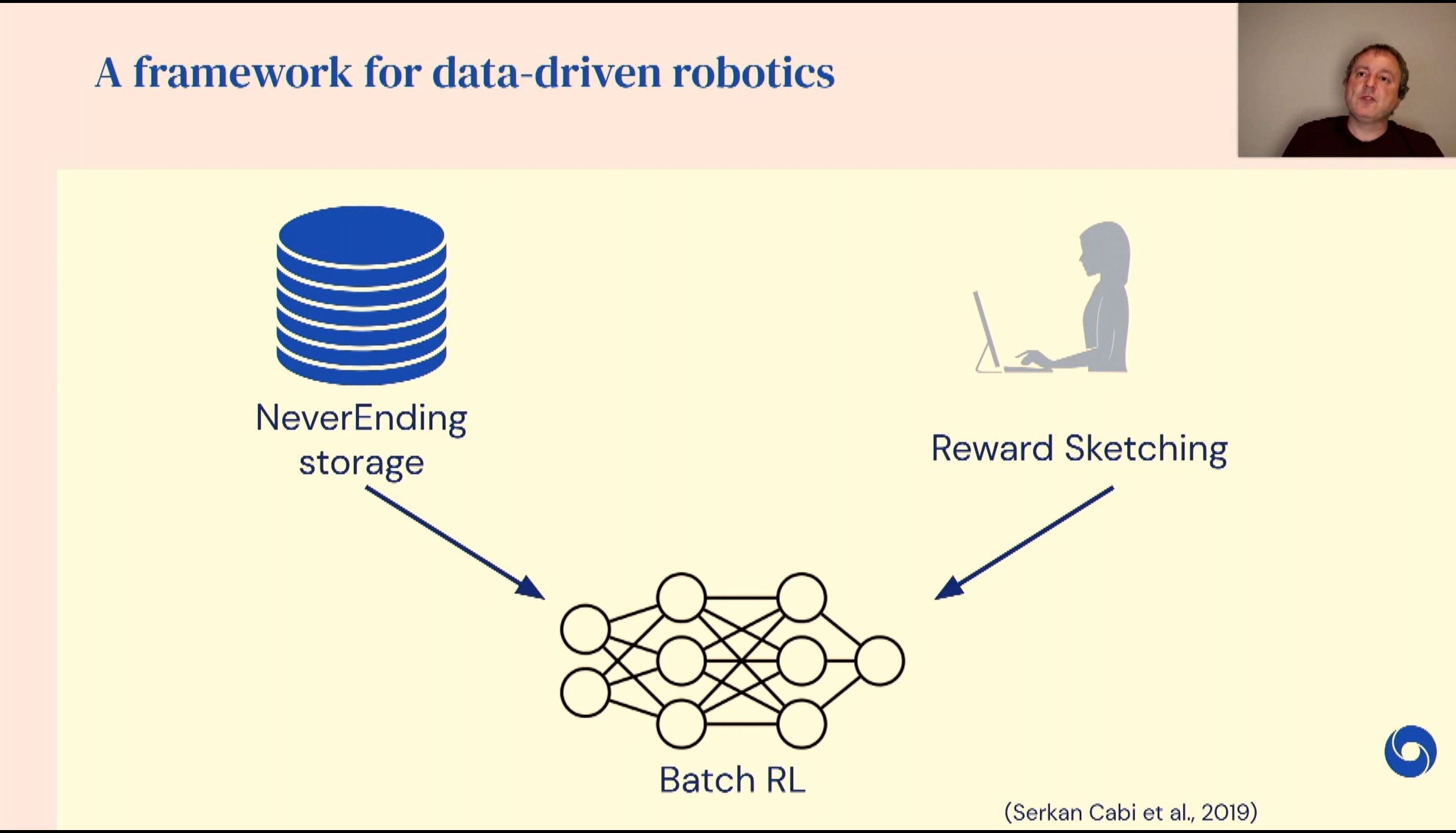
04:44PM EDT - Reward Sketching - listing human preferences
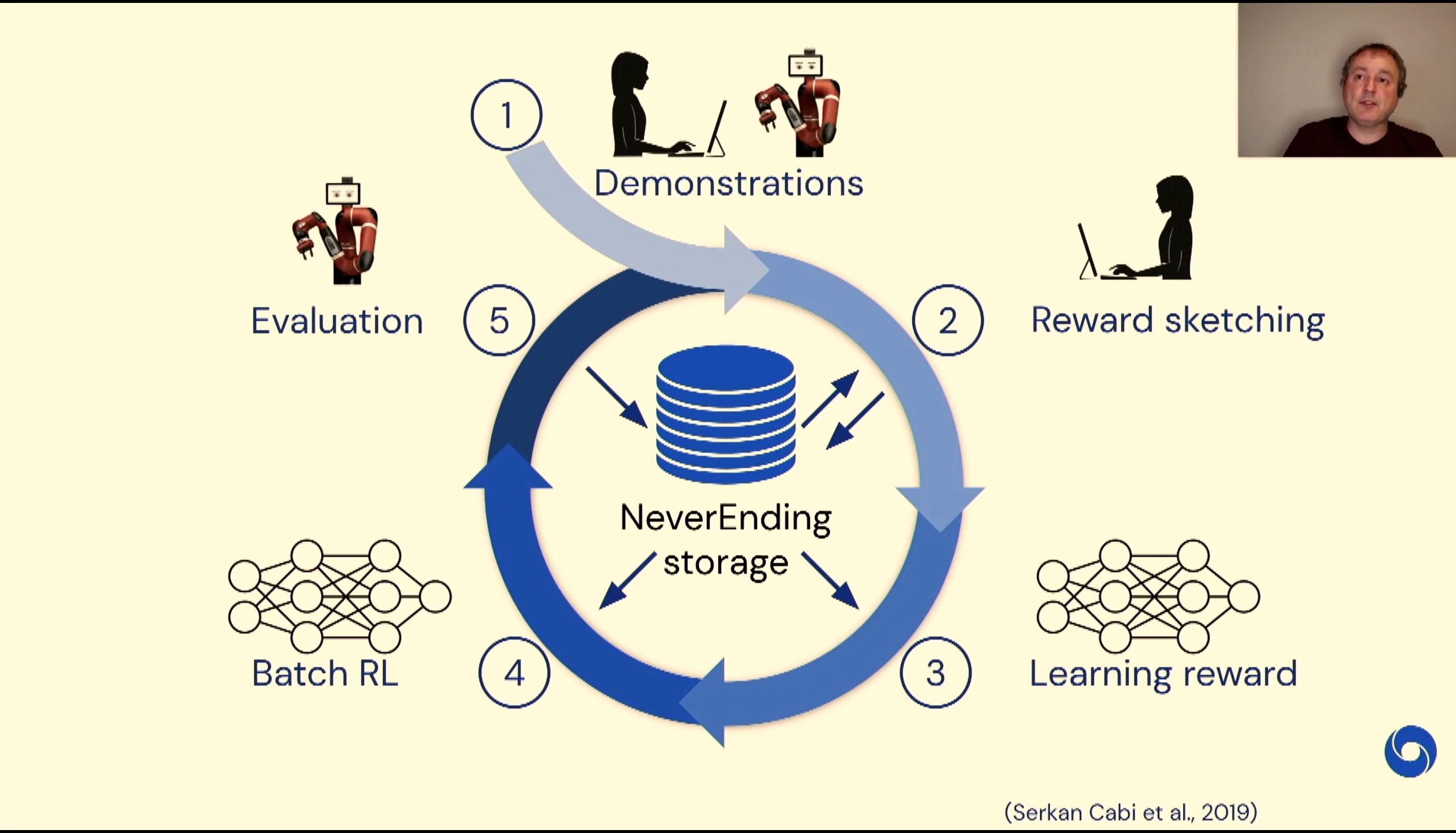
04:44PM EDT - Scale up reinforcement learning in robotics
04:45PM EDT - Never throw any data away, no matter how bad it is

04:45PM EDT - Neverending storage
04:45PM EDT - failed experiments, random policies, interferences
04:45PM EDT - Initiate with as good data as possible
04:46PM EDT - humans annotate random attempts to indicate where the rewards are
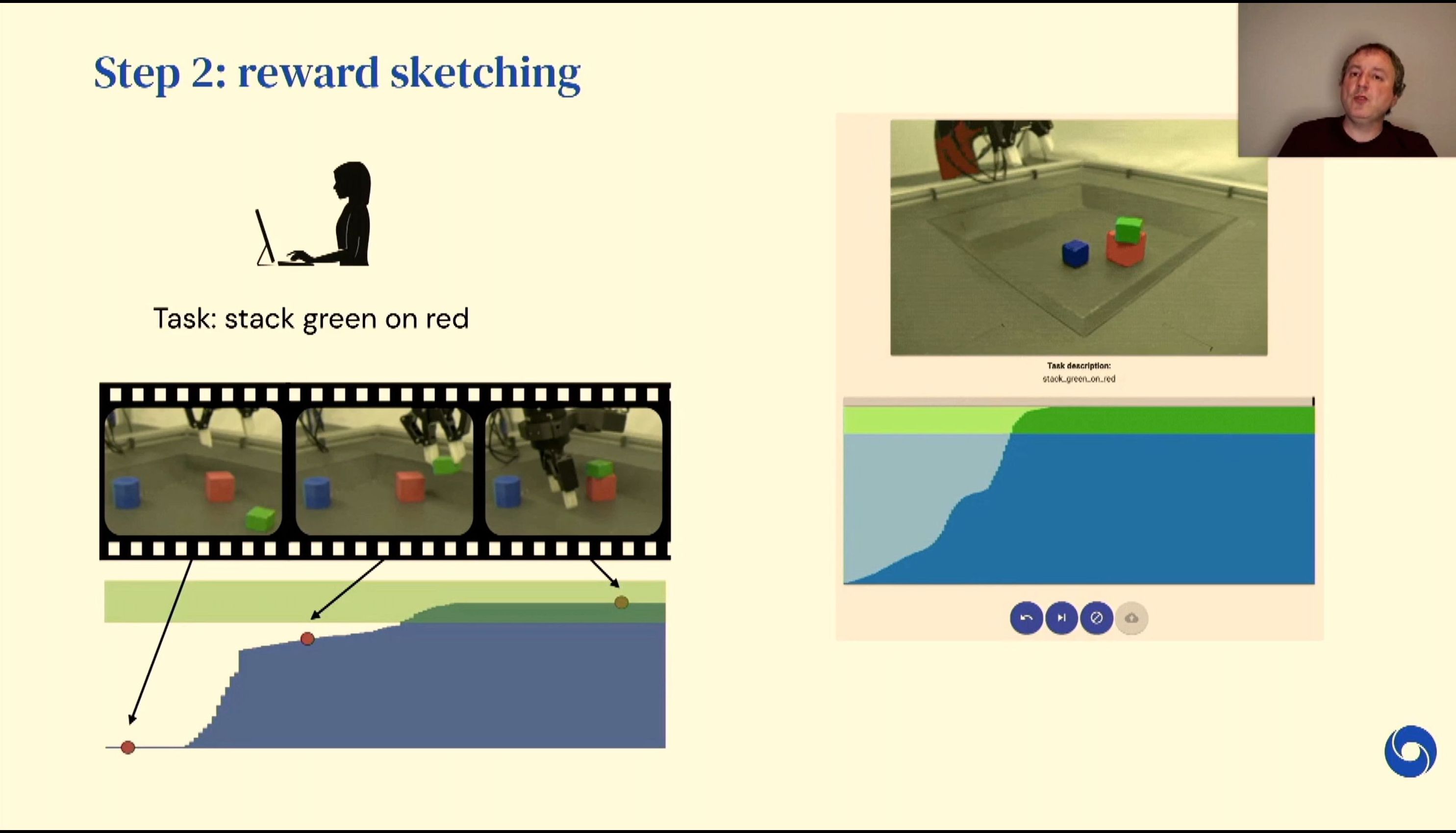
04:47PM EDT - Protein folding or robotics can be difficult to decide how close you are to the goal, so learn programs that assign rewards from programs
04:47PM EDT - Batch RL

04:48PM EDT - Everything that the robot does with all this data is stored, and used for future iteration laernings
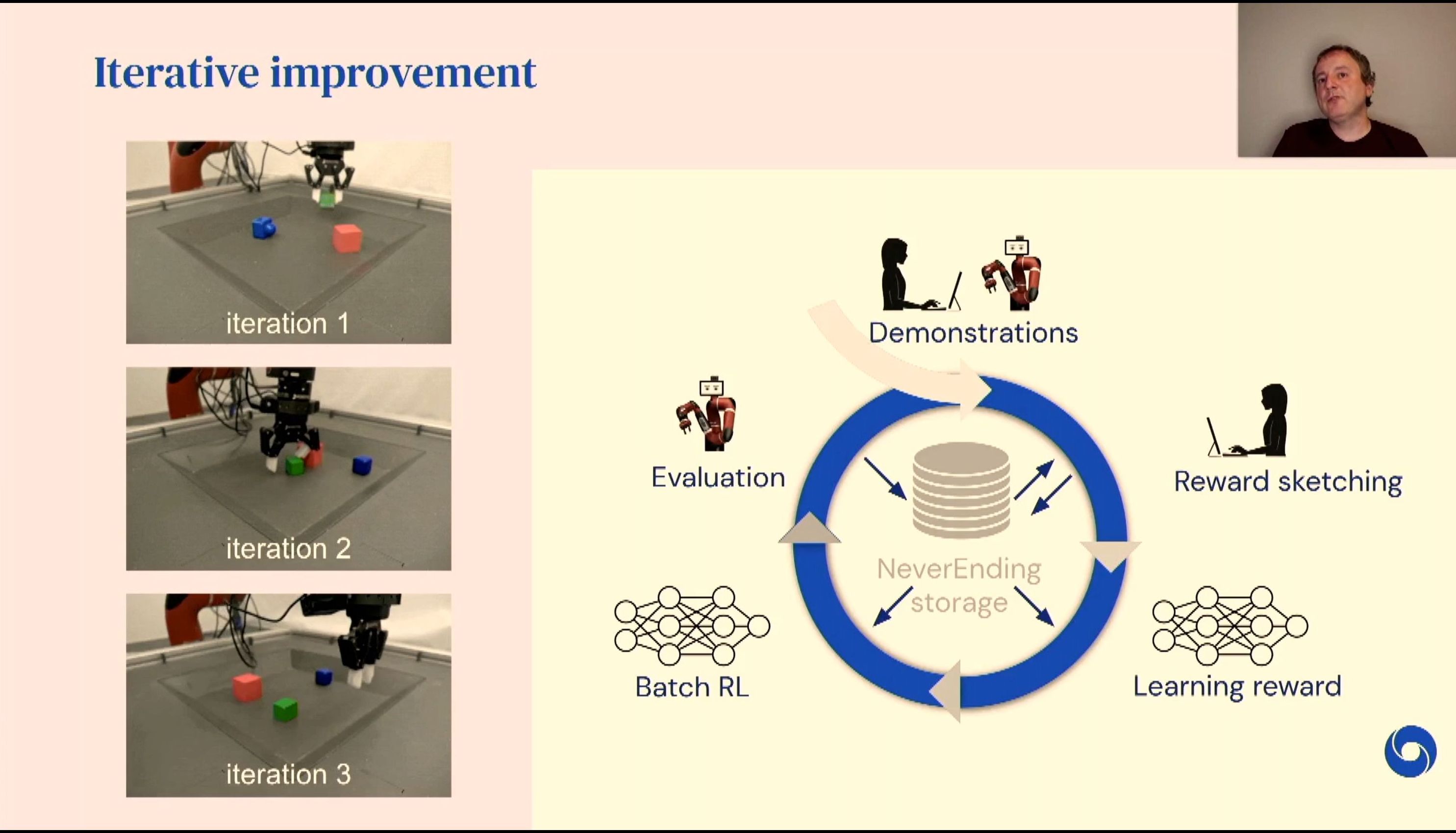
04:48PM EDT - Behaviour with adversarial environments

04:49PM EDT - Need to train on clean examples but also bad data to observe failure
04:49PM EDT - understanding failure is critical to learn good behaviour
04:49PM EDT - eventually outperform humans
04:49PM EDT - Handling non-scriptable objects

04:50PM EDT - Iterative improvement in dataset quality over time
04:50PM EDT - combined with policy optimization
04:50PM EDT - better and more diverse data to improve

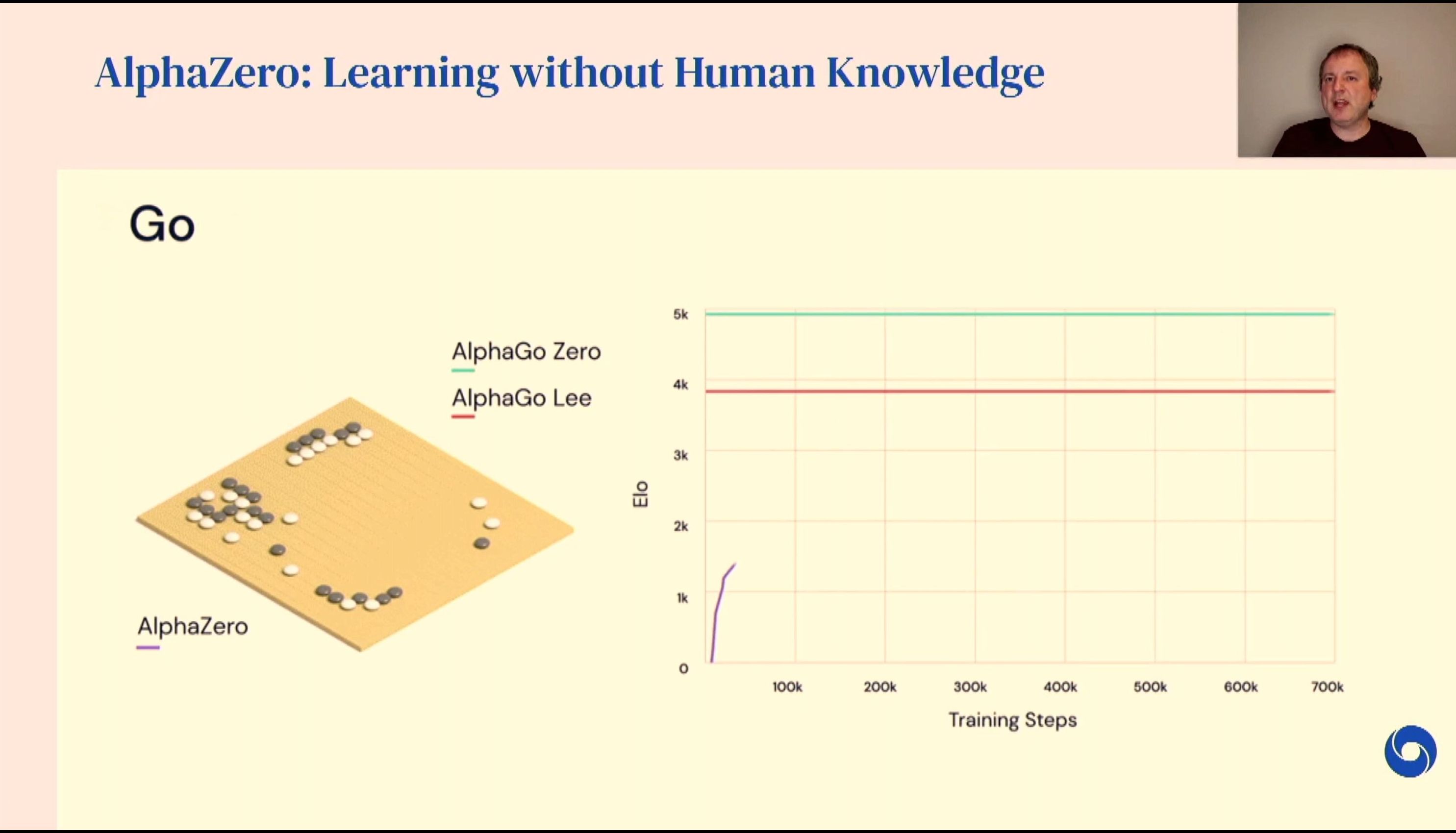
04:50PM EDT - Now for Go

04:51PM EDT - Simple game for structure, complex game to master
04:51PM EDT - Here's a search tree for brute force search

04:51PM EDT - Very difficult to point score a given board position
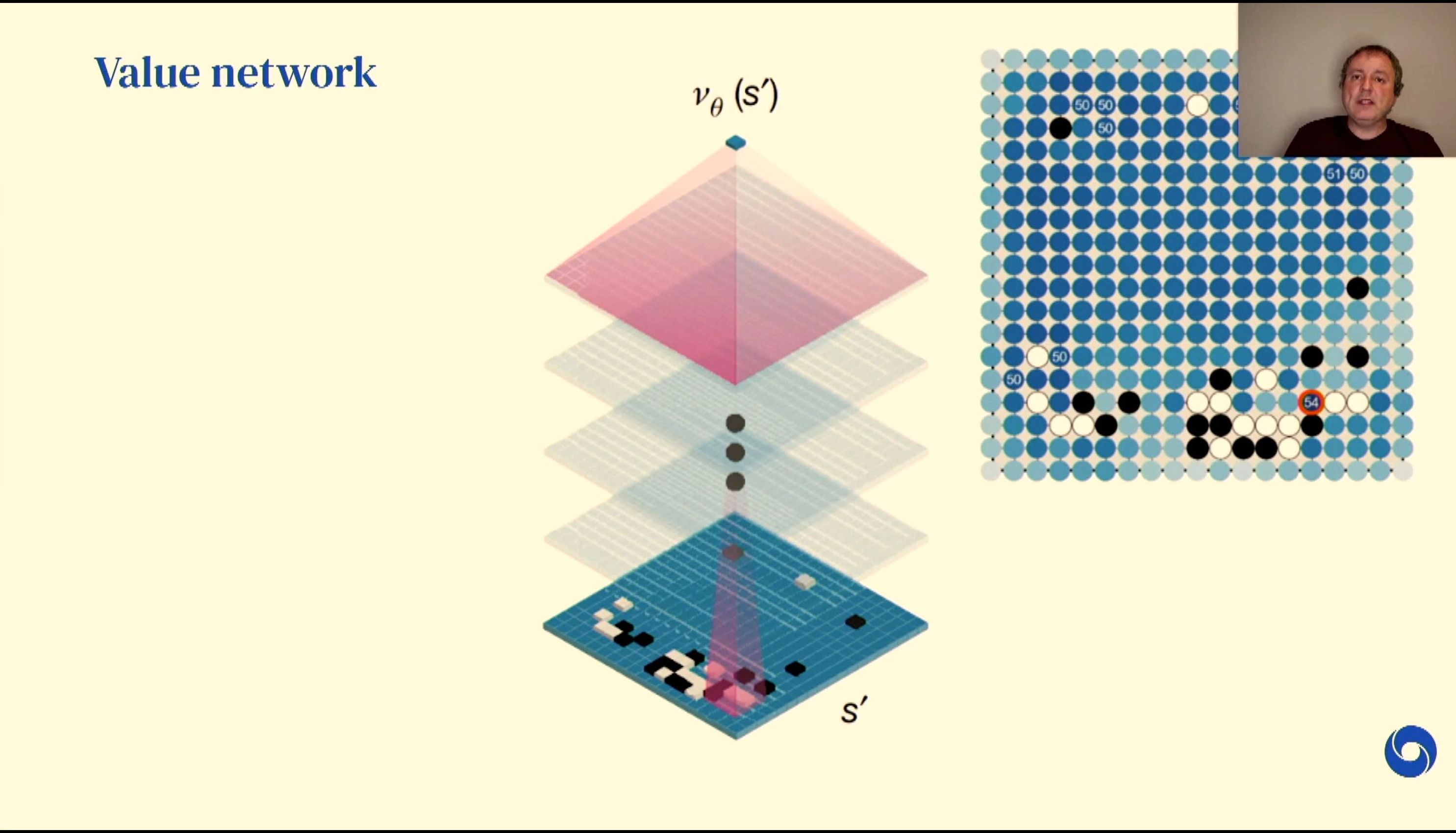
04:52PM EDT - Value network - use likelihood of winning from a given position based on previous games known as future stones
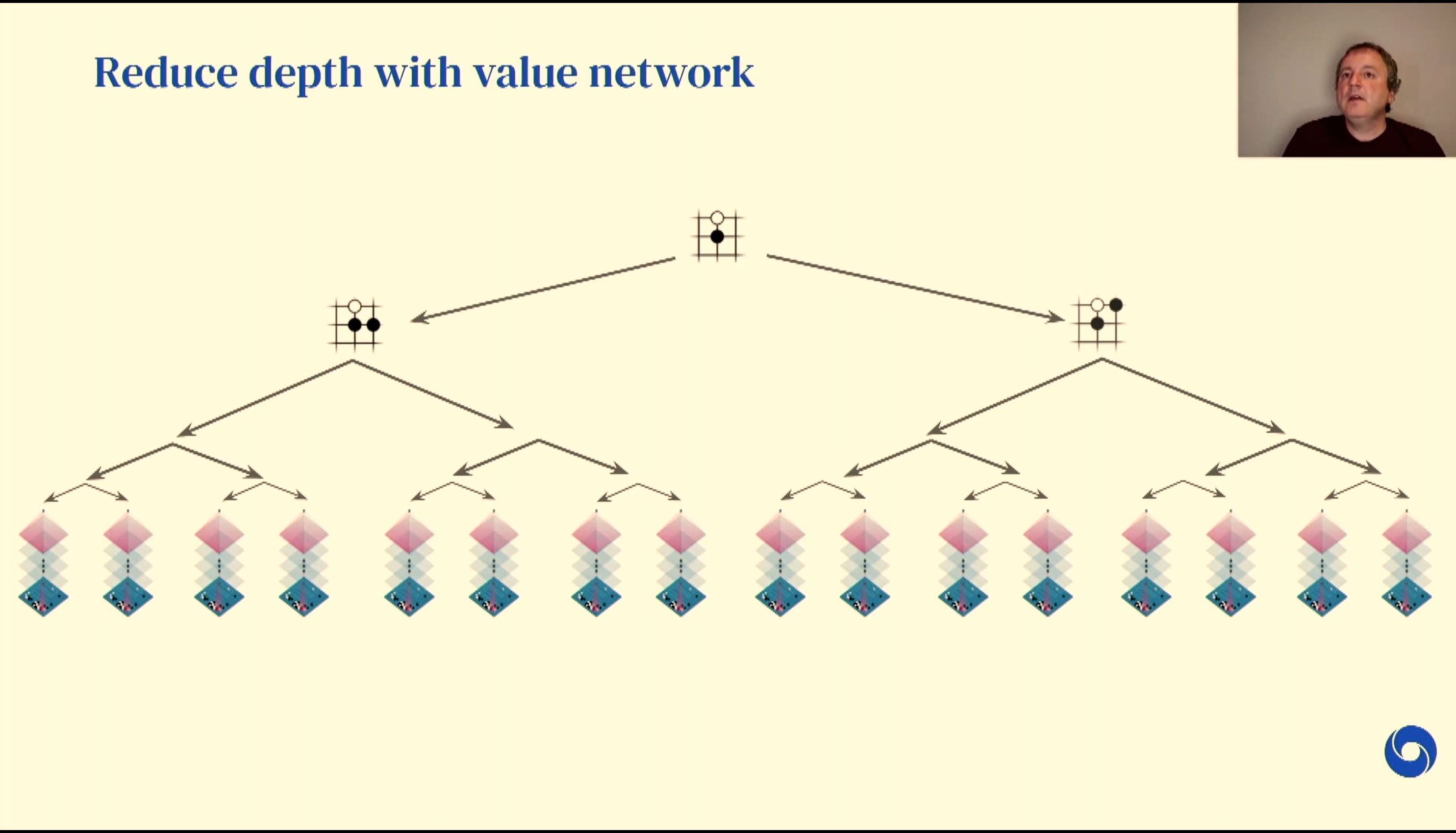
04:52PM EDT - End up with a value network to explore branches in a search tree
04:52PM EDT - No need to analyse future board positions that are known to give losing games
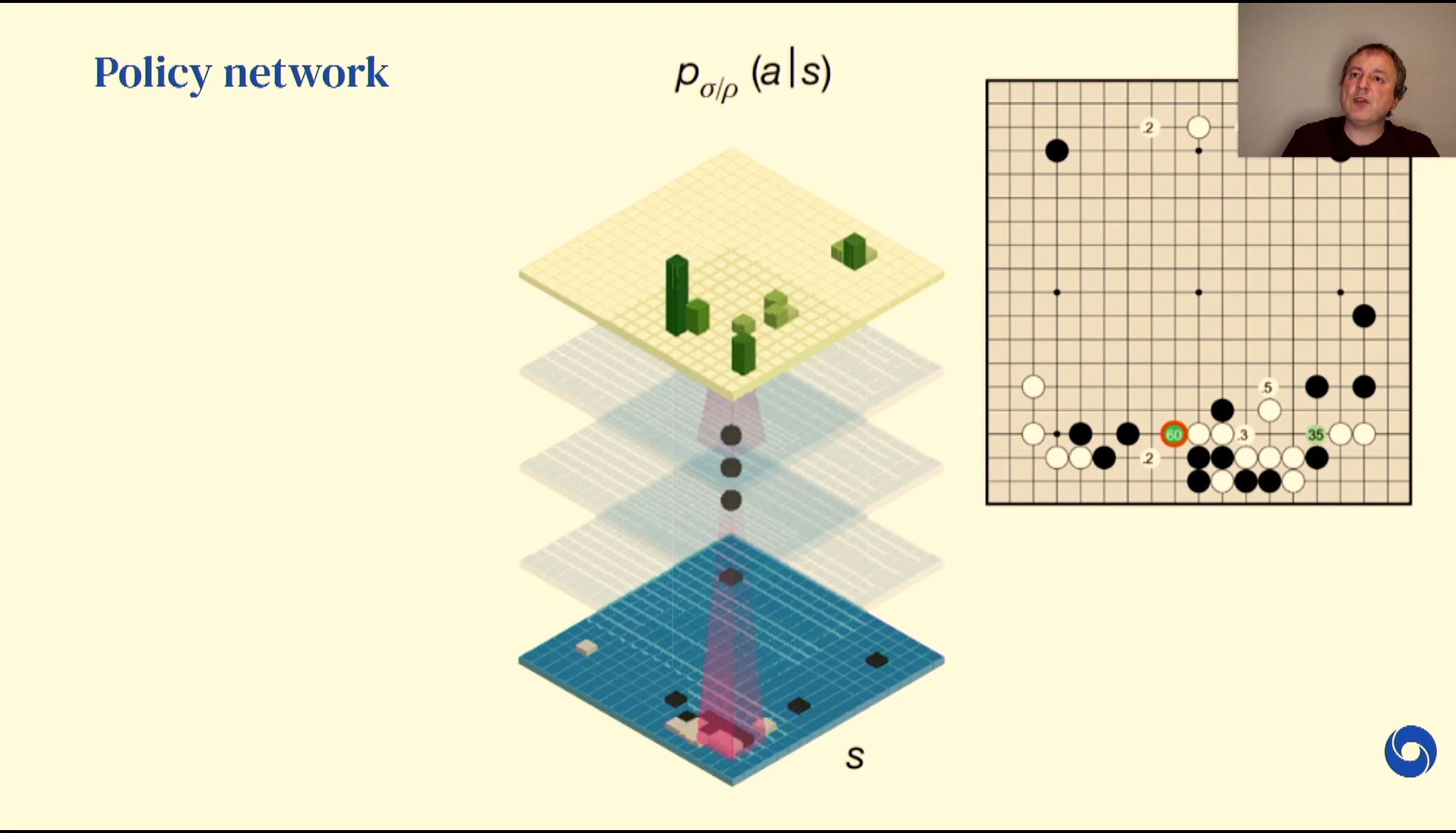

04:53PM EDT - Policy network to indicate which are the best moves, to reduce search even further
04:53PM EDT - reinforcement learning helps build these training regimes and policies
04:53PM EDT - Pruning the search space is critical
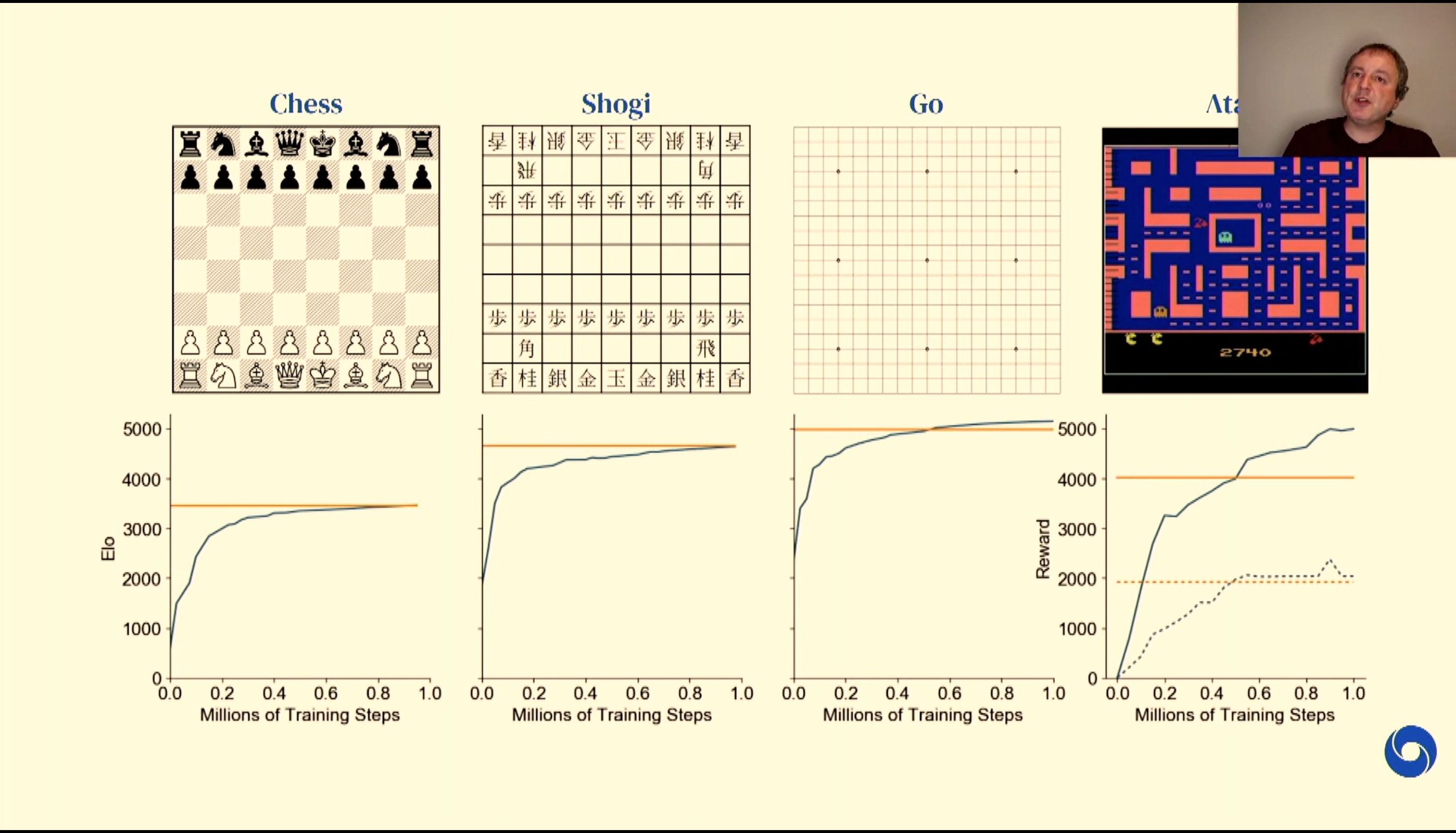
04:53PM EDT - Expand search beyond Go for Chess, Shoji
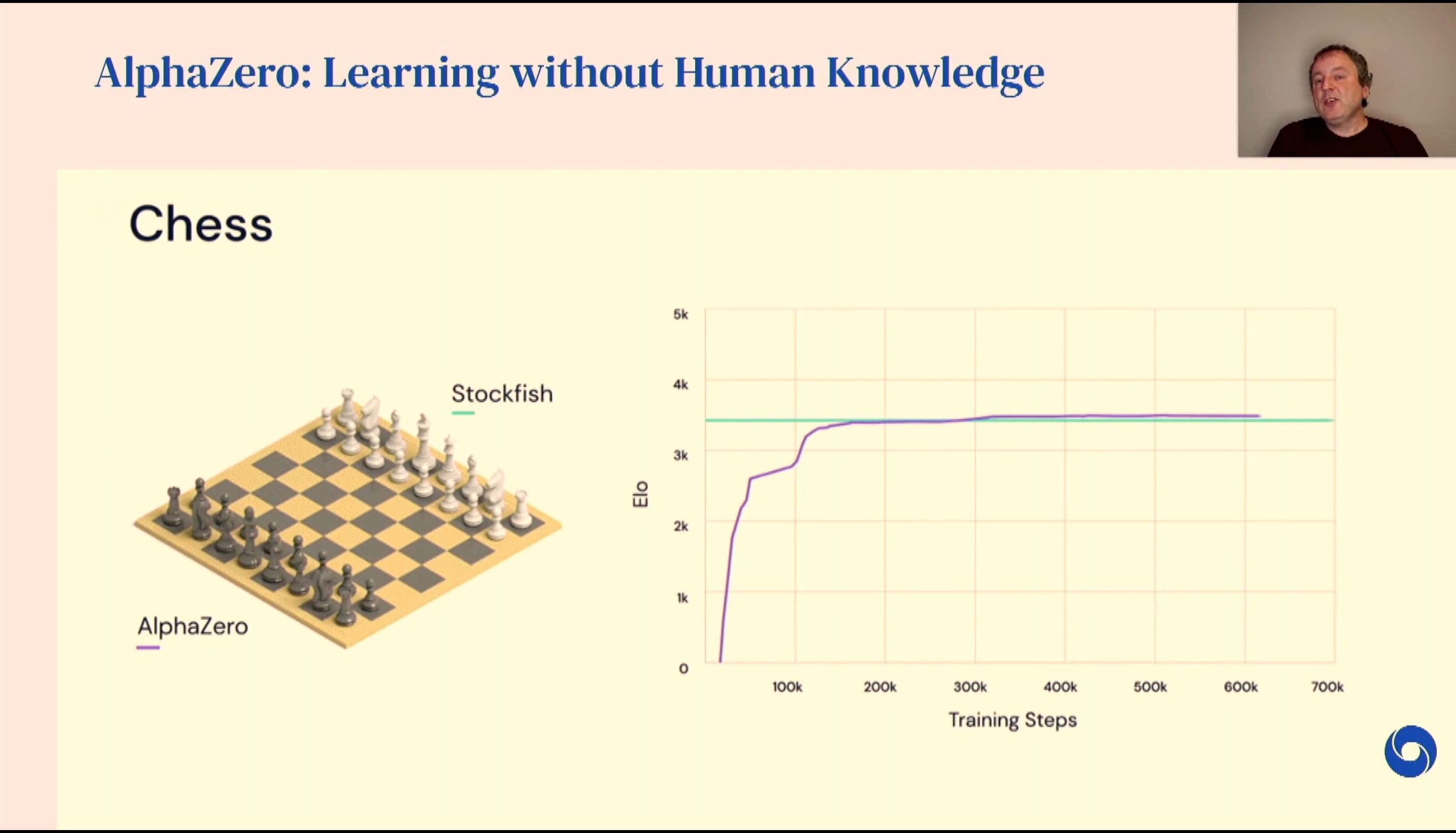
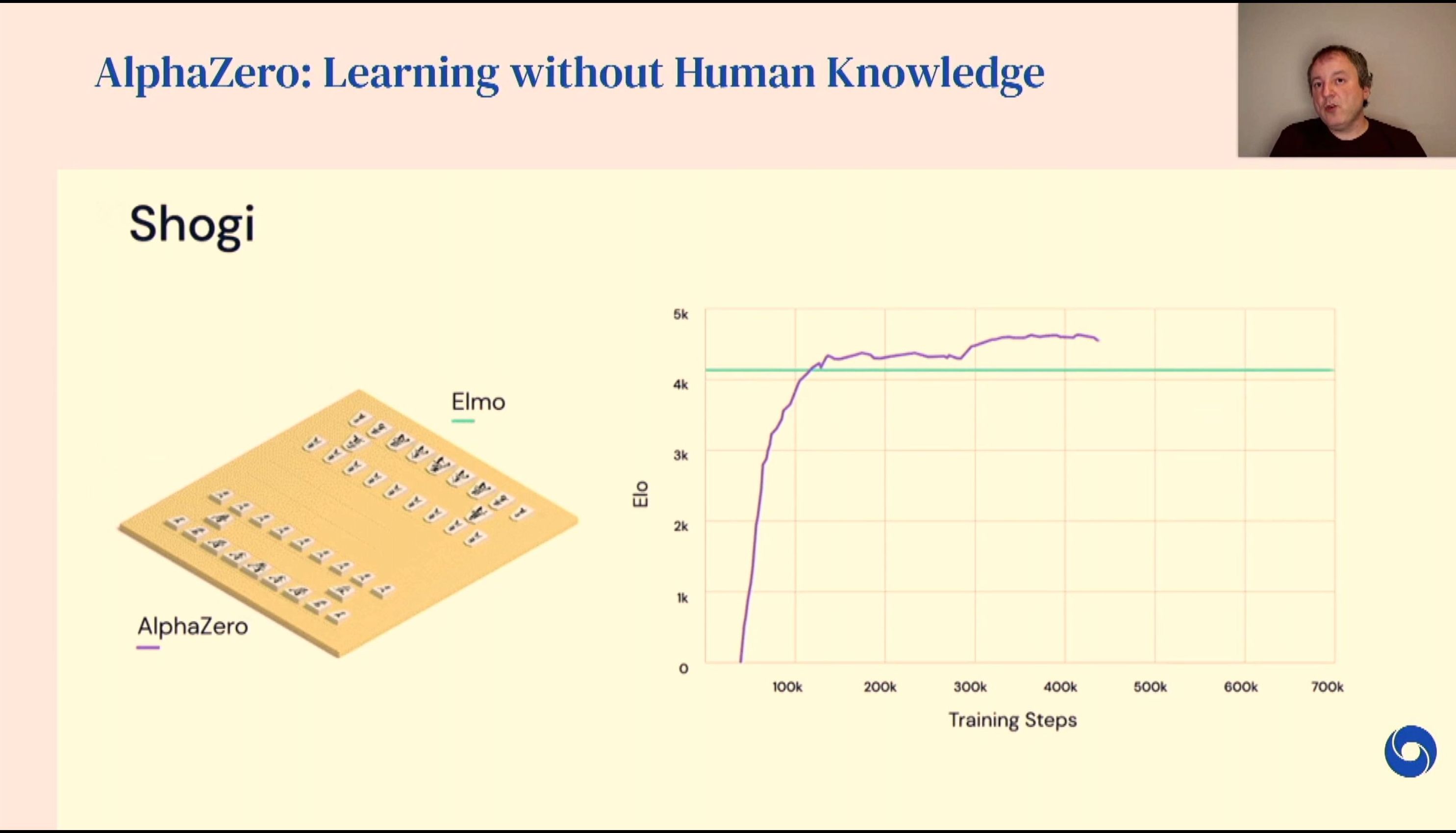
04:54PM EDT - Model Based Reinforcement learning - learning the effects of actions
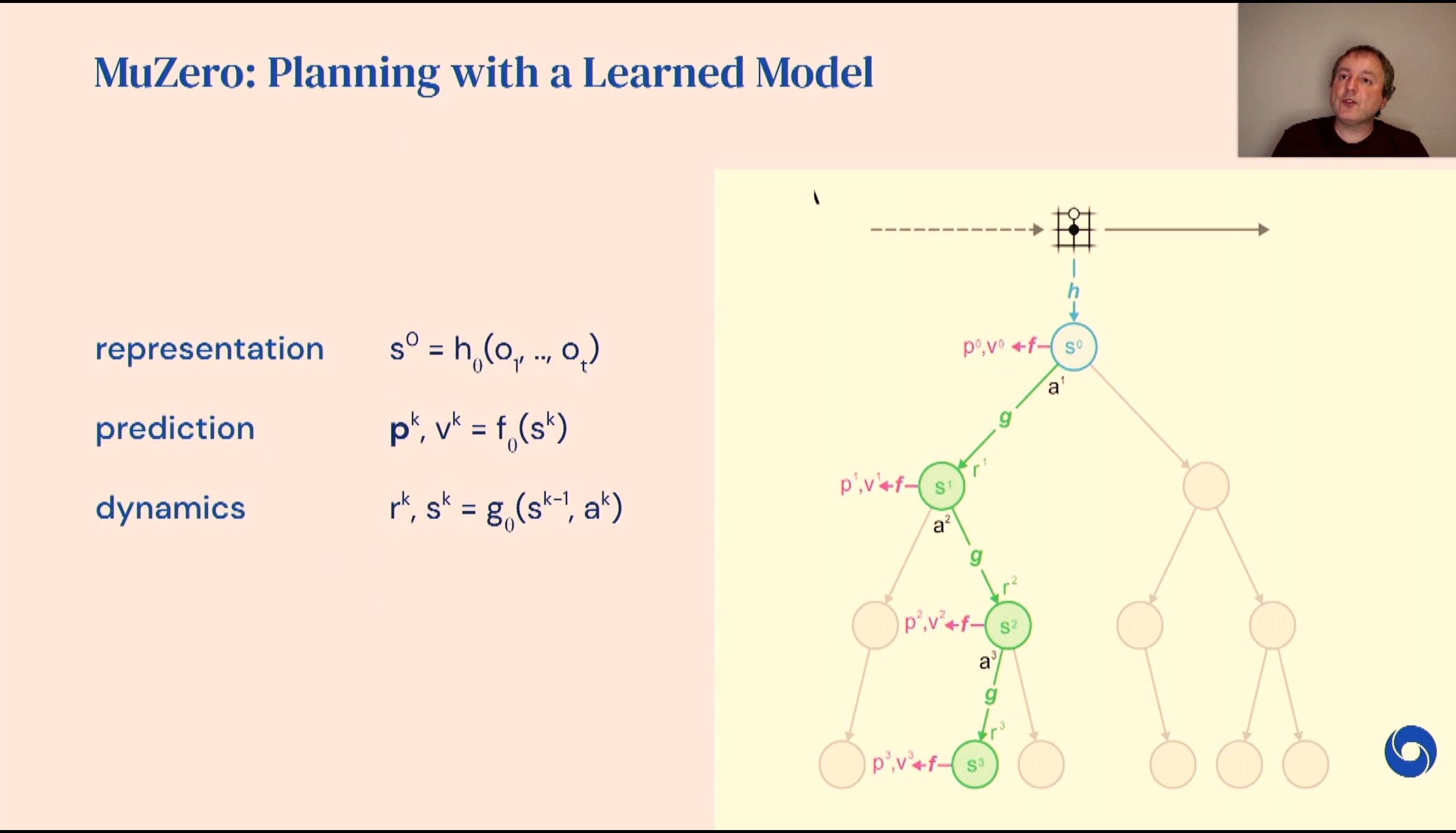
04:55PM EDT - State trees are predicted imaginary states
04:55PM EDT - Allows for simple games, but also complex visual environments
04:55PM EDT - Building models of things like drug discovery etc is tough

04:56PM EDT - Graph neural networks
04:56PM EDT - Interactions between particles -> edges in a graph
04:56PM EDT - interactions processed through neural networks
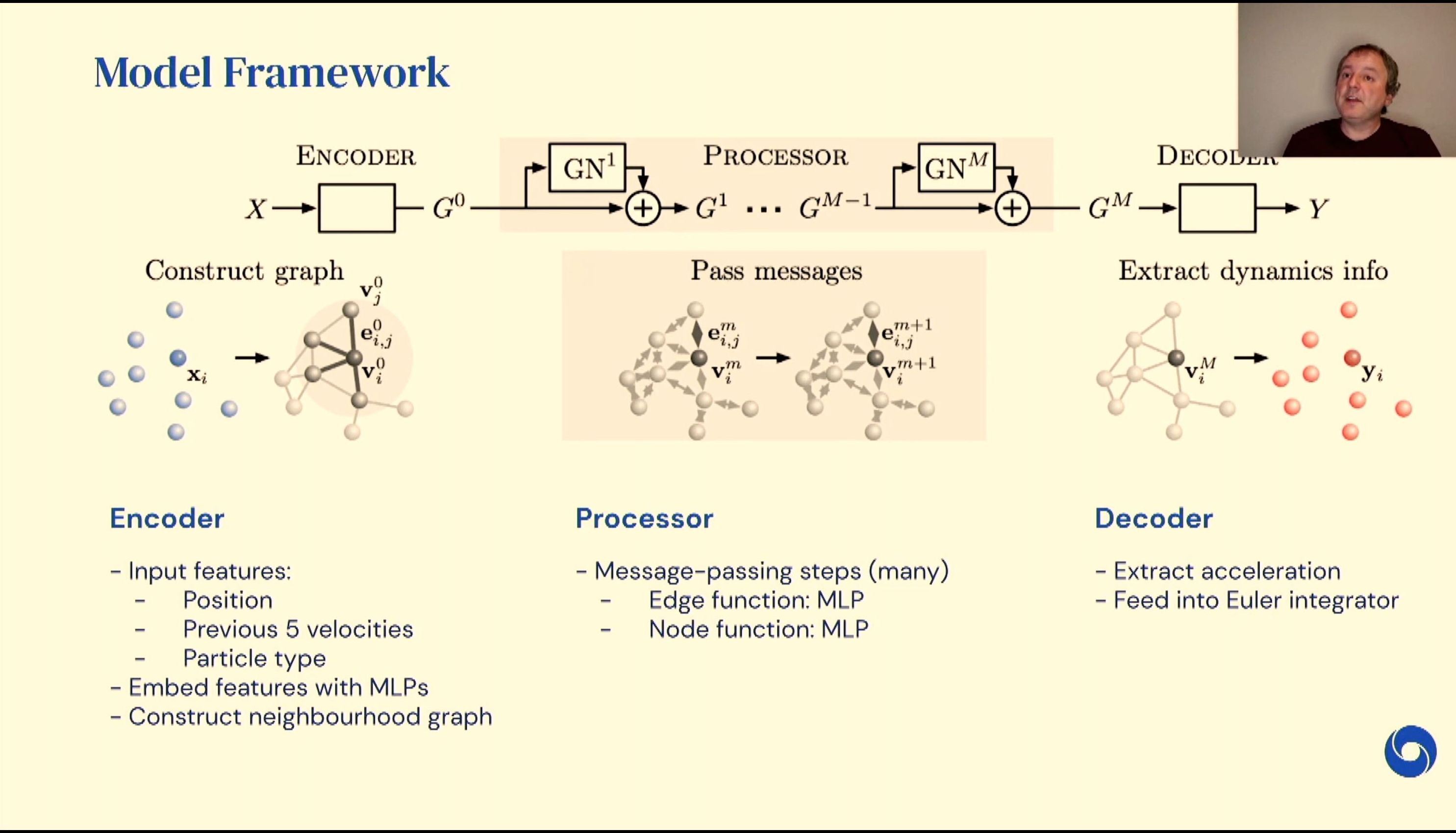
04:56PM EDT - Simulate phenomena
04:57PM EDT - Predicting reality and surpassing physically accurate simulations

04:57PM EDT - This needs a lot of compute

04:57PM EDT - Simple answer is that scaling compute works! More search means better results, more iterations gives better results
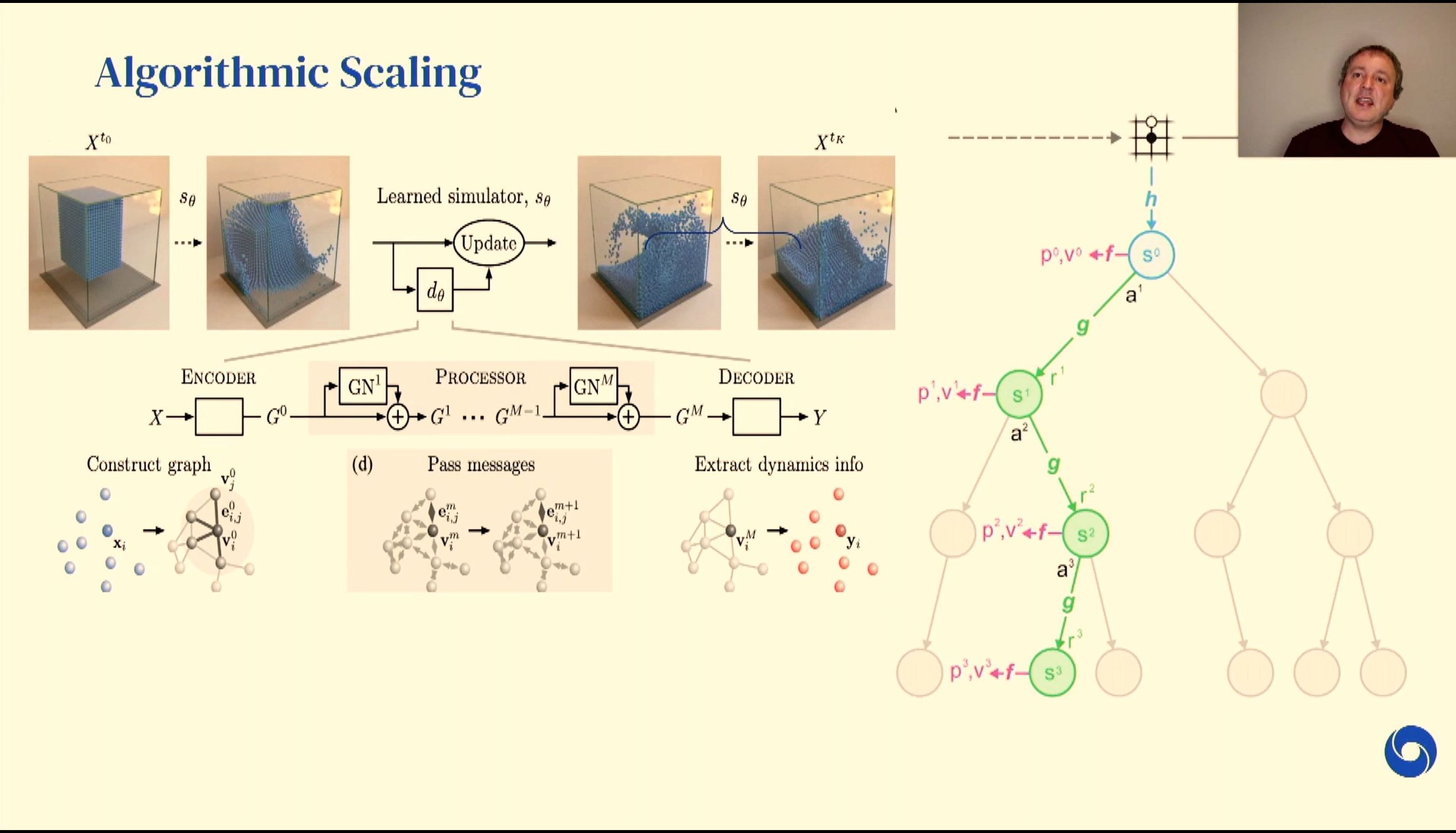
04:58PM EDT - Also allows for internal training consistency

04:58PM EDT - Compute scales, intelligence is tougher
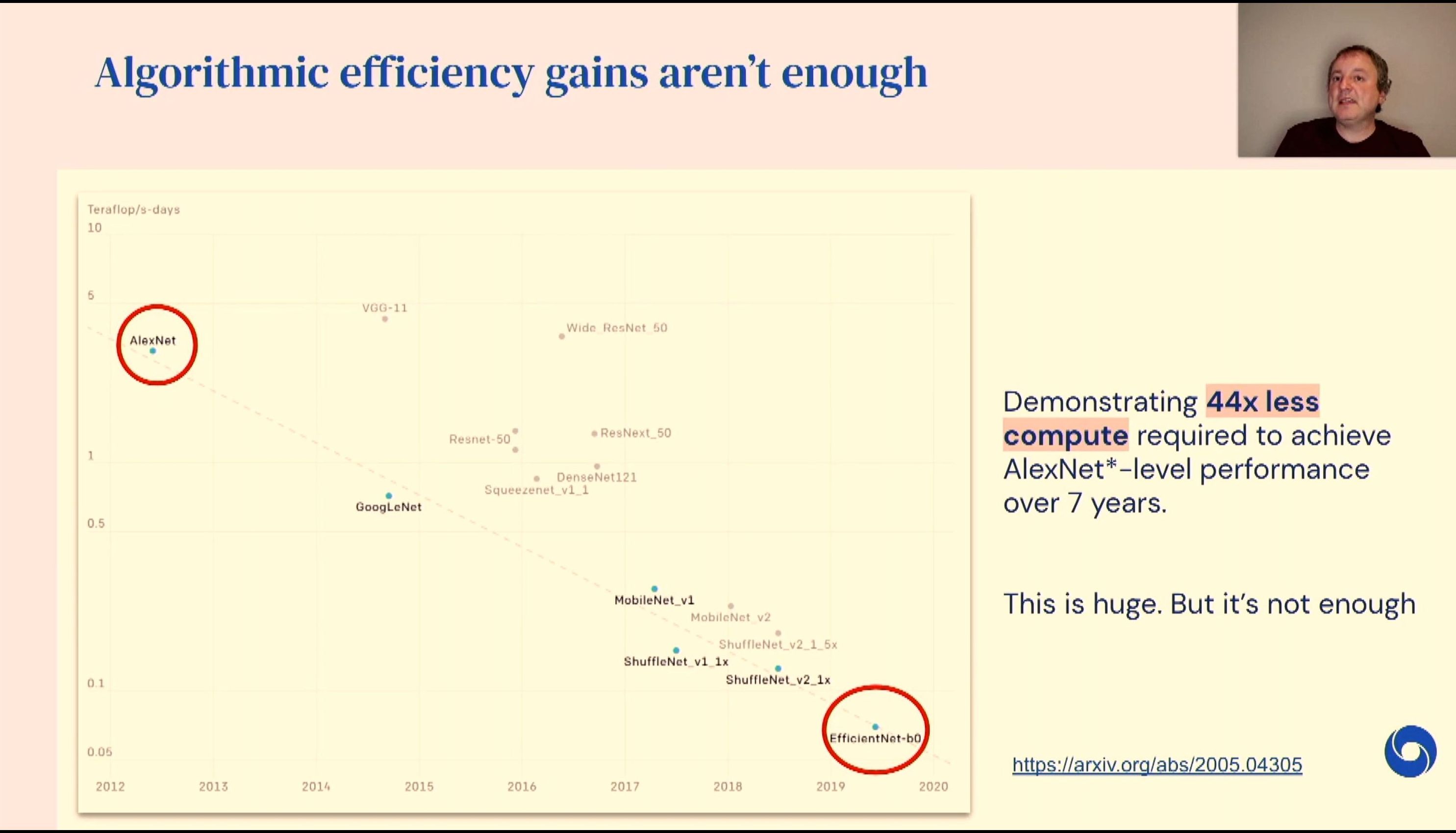
04:59PM EDT - Algorithms are more efficient now, but still not enough. Networks have been growing and growing
04:59PM EDT - Compute demand is 10x year
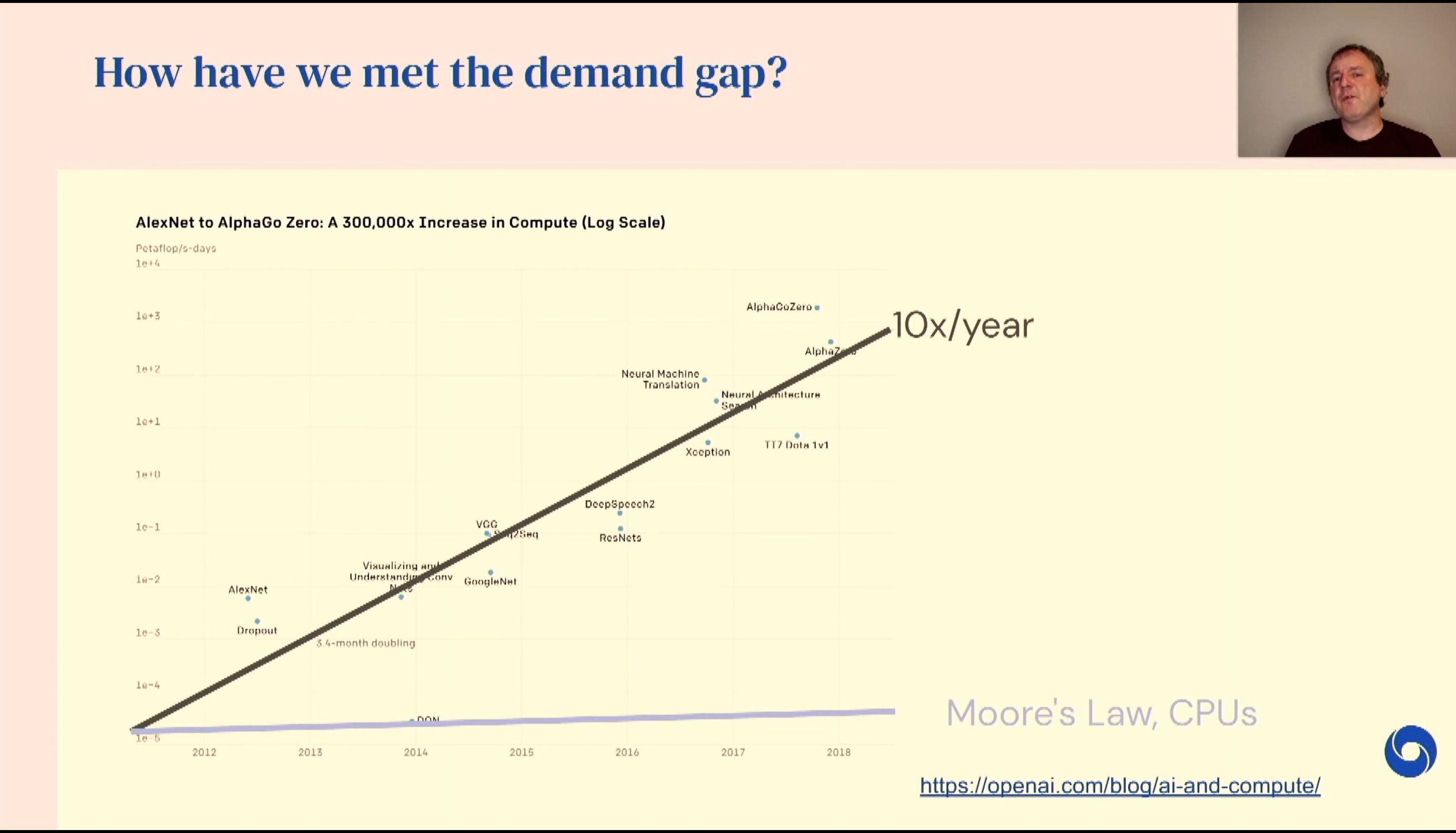
04:59PM EDT - Single CPU has stagnated
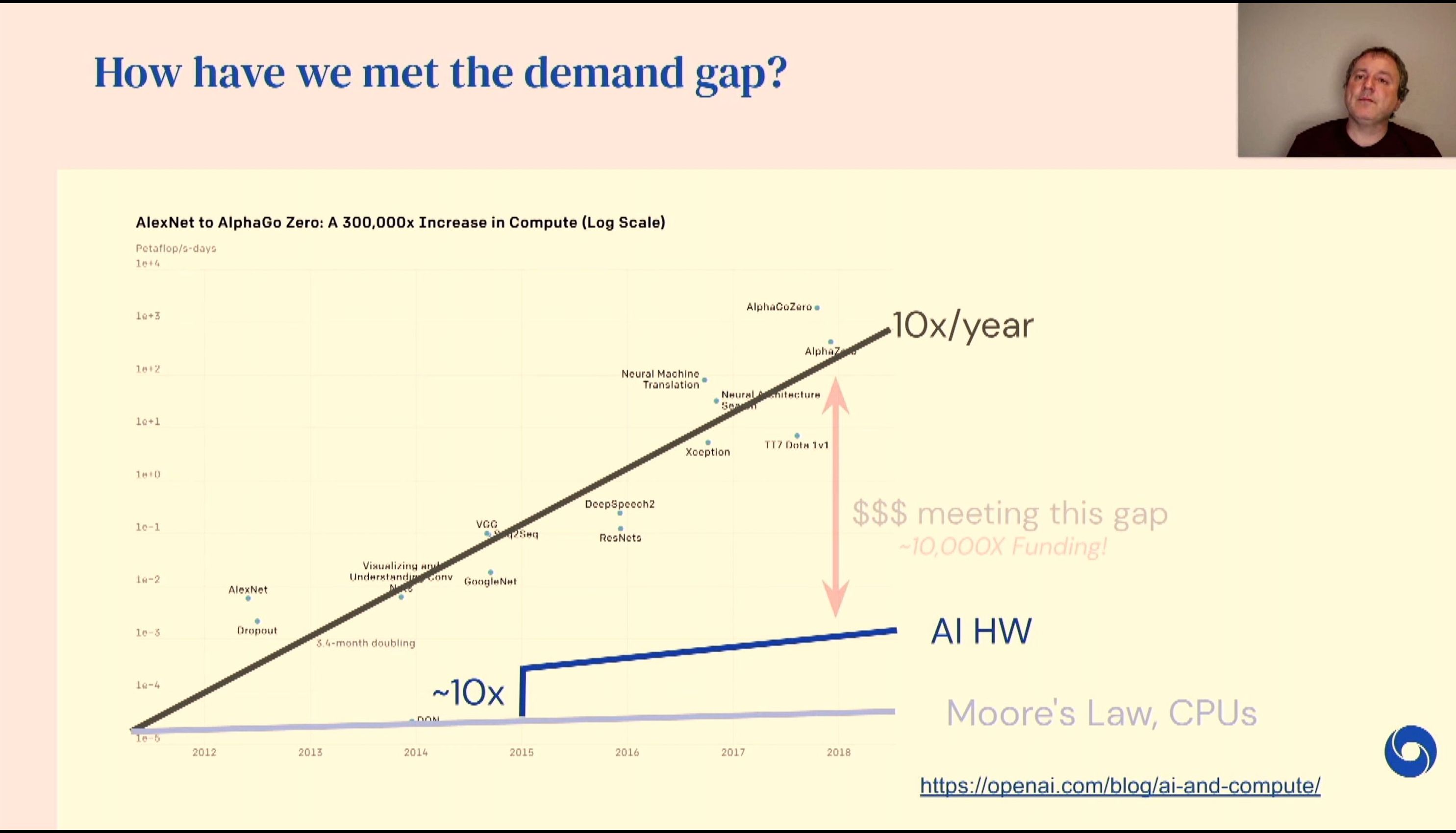
04:59PM EDT - Usign $$$ to meet the requirements
04:59PM EDT - Funding is still here, but not infinite

05:00PM EDT - Might be harder to make more fundamental breakthroughs without better hardware

05:00PM EDT - Three opportunities for the road ahead
05:00PM EDT - 1. Stop thinking about chips - think about systems

05:00PM EDT - Focus on whole systems
05:00PM EDT - Research at scale is about people

05:01PM EDT - Infinite backlog of work
05:01PM EDT - How much compute do you want? All of it!
05:01PM EDT - Big stack can product lots of opportunity but also lots of waste
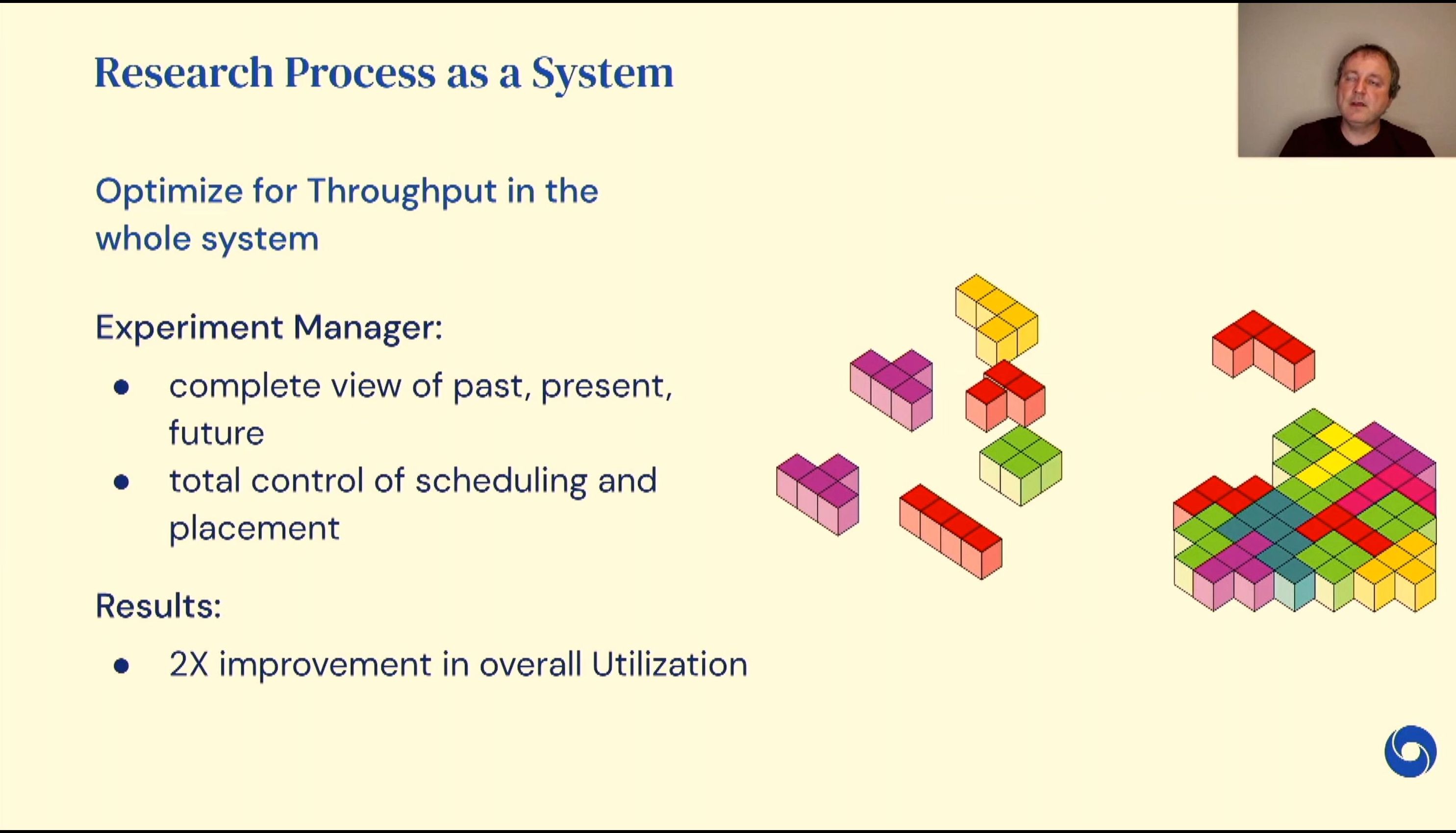
05:01PM EDT - Experiment manager -reorder the workscale to improve basic metrics
05:02PM EDT - better packing of experiments = 2x utilization
05:02PM EDT - Sustained perf/$ over the whole program

05:02PM EDT - TCO
05:02PM EDT - Best case is 70% FLOPs
05:02PM EDT - Average is only around 20%
05:03PM EDT - This number is consist across any silicon
05:03PM EDT - performance increases, but research workloads doesn't increase utilization

05:03PM EDT - Peak perf isn't a good predictor
05:03PM EDT - Sustained Perf/$ has lots of facets
05:04PM EDT - Plenty of reasons - IO, memory, startup time, starve for data, contention, amdahl
05:04PM EDT - Compiler lag
05:04PM EDT - Job contention at any point in the system
05:04PM EDT - Python runtime
05:04PM EDT - Everywhere we look, there are monsters that reduce utilization

05:05PM EDT - With 20% utilization, individual chip perf doesn't matter. But system perf/$ matters. Designing chips is fun, but design the system top down

05:05PM EDT - What ideas come out from this approach?
05:06PM EDT - Relies on integration of communities to co-design the systems of tomorrow

05:06PM EDT - 2. Embrace the point that there's not much room at the bottom
05:07PM EDT - What happens to Warehouse computers when there's no room at the bottom?

05:07PM EDT - but what actually matters

05:08PM EDT - If we used just Si for throughput with simple logic, can do 1000% at wafer scale
05:08PM EDT - True cost of power is 1000x

05:08PM EDT - Racks are less about the silicon, more about everything else

05:09PM EDT - Accelerate trends - move everything into silicon
05:09PM EDT - Even if it costs more
05:09PM EDT - Build systems that are only necessary
05:09PM EDT - Support non-linear properties

05:10PM EDT - Needs a paradigm shift

05:10PM EDT - Datacenters used to just be clusters of off-the-shelf computers
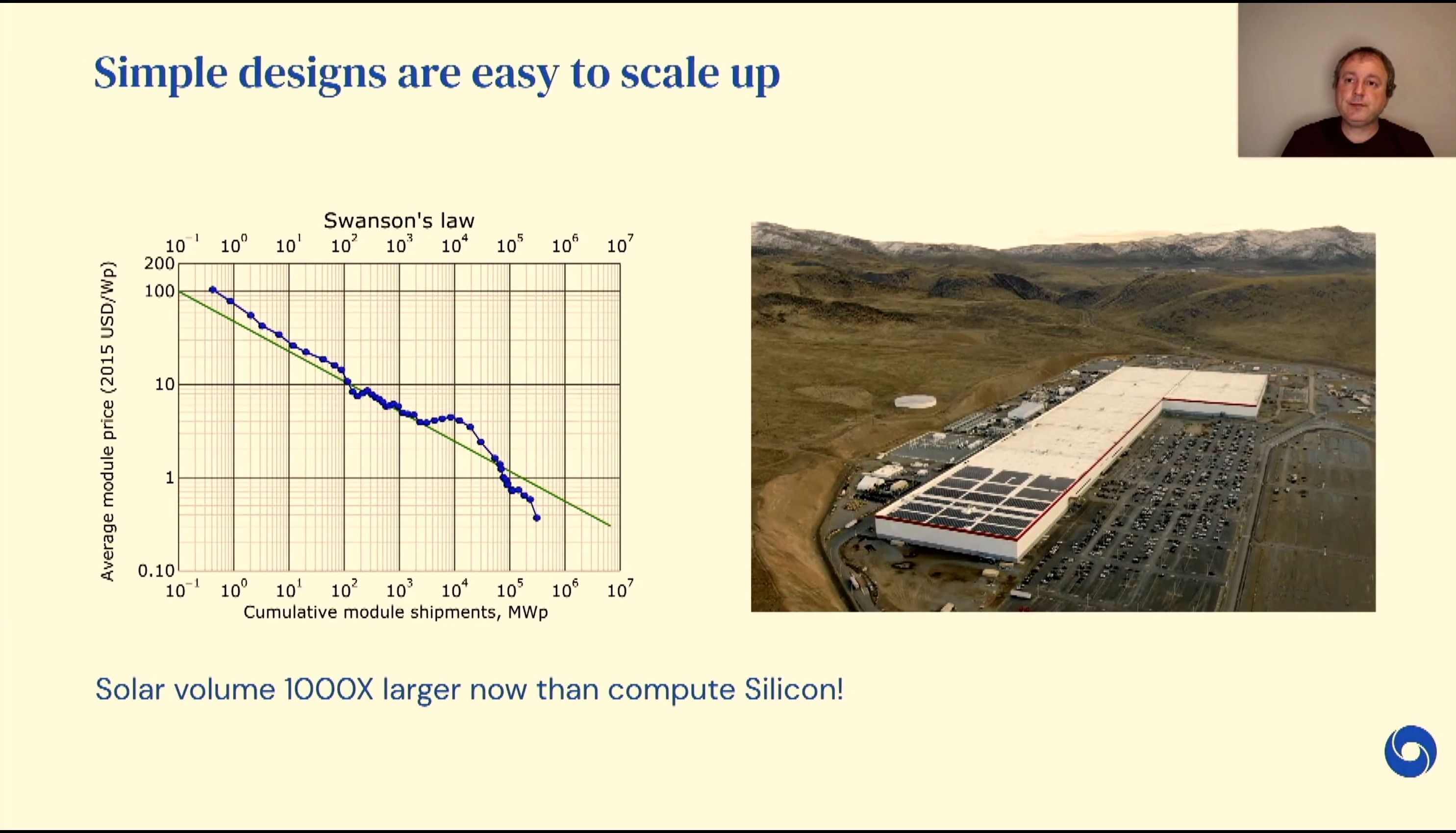
05:10PM EDT - Simple systems are easy to scale
05:11PM EDT - but now racks can be custom built to what each person needs
05:11PM EDT - We need a gigafactory moment for compute

05:11PM EDT - What about the software

05:12PM EDT - Distributed services - infrastructure had to be more complex to compensate

05:12PM EDT - Process nodes are normal, but big changes happen with paradigm shifts in the way we compute

05:13PM EDT - Complexity of software stack means that new paradigm shifts are harder to visualize

05:13PM EDT - New accelerators take a long time to become useful

05:14PM EDT - But AI is more constrained compared to consumer or normal server workloads


05:15PM EDT - Compiler friction reduces the ability to adopt new HW
05:16PM EDT - Can we use modern tools to build up older models to slim down the code base

05:16PM EDT - But magical compilers are like unicorns
05:17PM EDT - Deep Learning for compilers is the next step?

05:17PM EDT - Perhaps this is the future of machine learning?
05:18PM EDT - That last slide should have a 2020: Compilers section

05:20PM EDT - Q&A time
05:22PM EDT - Q: What fundamental chances will occur in the next few years? A: Accelerators that help with memory systems is an untapped area. There is work in the area, but we don't have any memory hardware that accelerated through ML to help ML
05:25PM EDT - Q: real life prediction vs phsyical law simulation speeds? Could it be applied to ray tracing? A: It's in the paper :) These ML simulations eventually become much faster - because we integrate more information with each cycle. So we can modulate the timescale as well as the courseness of the simulation, perhaps dynamically in the future. We have models where you can sample configurations and sothey give us a way to sample from a distribution that is not infinitely meaningless - you get samples that are useful. On Ray Tracing or generating structures, I don't think we've done it internally, but several papers have been made where people generate in-game structures based on ML. Also differentiable ray tracers that can be used with ML.
05:27PM EDT - Q: Big problems solved with RL? A: Understanding in the solution of Go/Chess/Shogi were significant. RL for control problems in robotics. Also datacenter cooling.
05:30PM EDT - Q: Is MLPerf a good set of benchmarks for the industry to go for? A: MLPerf is great is that it gives a general yardstick in some directions. We can tell some things about a system if it has MLPerf. The difficulty with RL and research, we don't want to know how fast one thing runs, we want to know how fast everything runs, even what we haven't written yet. We've also struggled how to add these requirements into MLPerf. Usually when we think about new systems we try to think about a phase space of perf - if you vary parameters, how does the performance change to give us an intuitive feel on how the system would perform. No one benchamrk is good enough, realistically it would be nice to do a search across many architectures that would give us an intuitive feel on how these systems work. But it's not practical. But MLPerf is a nice sweet spot.
05:34PM EDT - Q: Does using ML to create and optimize a 'special universal compiler' result in the problem of not knowing how it goes internally? wouldn't this lead to issues where rogue compilation or a biased compiler goes un-noticed? A: It depends on how we build it. Building any systems that translate without also thinking about some form of verification and those would be for systems that we rely on is not the right way forward - we have to also do some work on verification. Every transformation that the compiler would pick has to be correctness preserving, otherwise it doesn't work. The difficulty is that preservation, the abstractions, but we can't sacrifice correctness.
05:34PM EDT - That's a wrap. Next up is Google TPUs








0 Comments
View All Comments